Tokyo Dystopiaの設計思想
夏本番に向けて海に行ける体作りに励まないといかんなーと思いつつも、ついついDSのスターフォックスで遊んでしまうmikioです。さて今回は、人知れずリリースされている検索エンジンTokyo Dystopiaの概要と設計思想について述べます。
Hyper Estraierとの違い
Tokyo Dystopia(以下、TDと呼びます)は、新しい検索エンジンです。しかし、私が作ったもう一つの検索エンジンHyper Estraier(以下、HEと呼びます)の後継としては位置付けていません。Hyper Estraierの製品コンセプトは、「検索システムの需要が生じる様々なシーンで手軽に導入できる」ことです。言い換えれば、「いわゆるシロウトの人でも、お高い商用システムを買えない個人や小組織でも、ちょっとの努力で自分の要求を満たすシステムを構築できる」ことです。そのために、様々なファイル形式に対応したテキストフィルタを用意したり、各種のスクリプト言語バインディングを用意したり、便利な管理ツールやCGIスクリプトを付属させたりしています。典型的な使い方のひとつであるWebサーバの検索システムの構築方法についてはマニュアルにチュートリアルとして書いていますし、ファイルサーバの検索システムを作るのも付属のコマンドを数回実行するだけです。
しかし、TDは違います。エンドユーザ向けではなく、完全にプログラマ向けのパッケージになっています。ツンデレどころか、ツンツンです。言語バインディングはないしフィルタもないしUNIX版しかないしマニュアルもそっけないし英語だし...といった具合です。TDの製品コンセプトは、「数年以上の実務経験のあるCプログラマが、mixiのような膨大なデータ量と尋常でないトラフィックに耐える各種の検索システムを、実サービスの要件を満たす最適化を施しながら、コードの8割程度を再利用して実装できる」ことです。
つまり、TDはいわば業務用検索エンジンであり、一般のユースケースには向いていません。個人で企業で学校で手軽に検索システムを構築するには相変わらずHEがオススメです。なお、「Dystopia」は「Utopia」(理想郷)の反意語だそうで、現実主義のツンツンな思想を表現するのに丁度いいかなと思って名づけました。APIの構造
TDは、文字N-gram方式とタグ付け方式の2種類のインデックス型をサポートし、それぞれに低水準と高水準のAPIを定義しています。つまり4種類のAPIが提供されます。

文字N-gram(以下、単にN-gramと呼びます)方式とは、例えば「あぶらかだぶら」を解析して、「あぶ」「ぶら」「らか」「かだ」「だぶ」「ぶら」などの文字単位で分解したトークンをインデックスに格納する方式で、TDは2文字毎(2-gramあるいはbi-gram)に分割したトークンを扱います。「あぶら」を検索するには「あぶ」の直後に「ぶら」が来ることを確かめる必要があるため、インデックス内で各トークンに関連付ける位置情報(posting list)には、文書番号と文書内での出現位置の双方を持たせます。
タグ付け(分かち書き)方式は、例えば「あぶらかだぶら」を解析して、「あぶら」「か」「だぶら」などの単語単位で分解したトークンをインデックスに格納する方式で、TDでは単語分解はアプリケーションの責任にすることで、任意の言語解析器を利用したトークンを扱えるようにしています。単語そのものが検索キーになるので複数のトークンの連接を確認する必要がなく、インデックス内で各トークンに関連付ける位置情報は文書番号のみになります。
N-gram方式は、切り出すトークンの数がめちゃくちゃ多い(文字数と同じ数になる)ことと、各々の位置情報のデータ量が大きいことから、インデックスが肥大化して検索処理も遅くなりがちです。しかし、検索漏れが起きないという利点と、自然言語処理を伴わないのでどんな言語(さらに言えば言語である必要すらない)にも適用できるという利点があるため、広く使われています。一方でタグ付け方式も、インデックスが小さくて済むという利点と、言語処理による高い検索精度が期待できるという利点があるため、これまた広く使われています。

低水準APIと高水準API
N-gramとタグの違いは分かったとして、低水準APIと高水準APIの違いは何でしょうか。低水準APIは単なるインデックスであり、対象のレコードそのものを保存しません。例えば、「あぶら」が番号15のレコードにあることをつきとめることはできますが、それだけでは15のレコードの文字列が何なのかはわからないのです。したがって、レコードそのものはインデックスとは別のデータベースに保存しておくことが重要です。インデックスを更新する際にも元のレコードの文字列が必要となります。一方で、高水準APIは索引付きデータベースであり、対象のレコードそのものを保存します。例えば、「あぶら」で検索して15番が該当することがわかったら、15番のレコードの「あぶらかだぶら」を取り出して提示することができます。ディスク容量を余計に食いますが、その方が管理は楽ですよね。
もうひとつの大きな違いは、低水準APIは単一のファイルに関連するデータをすべて格納しますが、高水準APIはディレクトリの中に複数のファイルに分けてデータを格納することです。高水準APIではスケーラビリティの確保について内部で工夫がされているので大規模なインデックスを手軽に構築することができますが、それらの工夫や分散処理をアプリケーション側で制御したい場合は低水準APIを利用するとよいでしょう。
上記以外にも、低水準APIでは文字列の正規化の責任はアプリケーション側が持つが高水準APIでは内部でよろしくやってくれるとか、高水準APIだと複合検索式があるけど低水準APIだとアプリケーション側の責任で論理演算を行うとかいった違いもあります。実装
TDはC言語で実装され、内部ストレージとしてTokyo Cabinet(以下、TCと呼びます)を利用しています。コード量はテストコード含めて13,000行くらいなので、TCの薄いラッパーと捉えてもいいくらいの規模です。実行効率の大部分はTCの性能に頼っていると言っていいでしょう。HEはQDBMを内部ストレージにし、TDはTCを内部ストレージにしているところが実装上の大きな違いではありますが、さらに根本的な違いとして、インデックスの構造が挙げられます。HEではハッシュ関数を利用したN.M-gram法と名づけた手法でインデックスの空間効率と検索処理の時間効率を向上させていたのですが、TDでは完全な位置情報付きのインデックスを使っています。なぜそうしたかと言えば、HEは比較的長いテキストを対象にする文書管理システムのような用途を主に考えていて、その場合にはN.M-gram法による高い圧縮率が期待できますが、TDではそれよりもかなり短いテキストを対象にする名簿検索のような用途を主に考えていて、その場合には前方一致検索や曖昧検索を可能とする位置情報を保持しておいた方が利点が多いと判断したからです。
また、HEではスコア情報をインデックス内に保持しますが、TDは位置情報のみを保持します。したがって、スコア情報はインデックスとは別途に保持する必要があります。例えばユーザ検索で最終ログイン時間が新しい順で結果を表示したい場合には、インデックス内のスコア情報ではなく最終ログイン時刻DBのキャッシュを引いて並び替えを行うことになります。
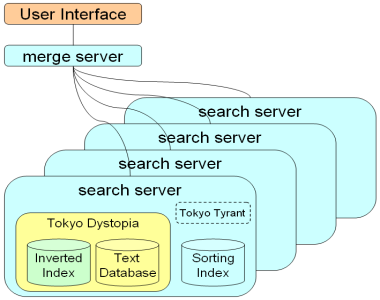
TDはネットワークサーバに組み込むことを想定しています。CGIスクリプトなどに組み込んでWebサーバ経由で呼び出すことももちろん可能ですが、その方法だと複数のプロセスが別個にインデックスをメモリ空間に載せることになるので、効率が悪くなります。それよりもインデックスと接続した単一のプロセスがマルチスレッドで並列処理できる方が効率的で、さらにそれを複数のマシンに分散させるのが現実的なソリューションになるでしょう。ネットワークサーバのプログラムを実装する難易度は決して低くはありませんが、Tokyo Tyrantやlibeventなどのユーティリティを使えば最近はだいぶ楽になりましたので、仕事で取り組むのも現実的な範疇だと思います。
まとめ
業務用検索エンジンTokyo Dystopiaの設計思想について述べました。大抵の検索システムはHEで構築できると思いますしその方が楽なのですが、自分でカリカリにチューンした検索システムを作りたい場合にはTDを使っていただけると幸せになれるかもしれません。現在、TDをベースとしたmixi内の検索システムを絶賛開発中ですので、近々お披露目できると思います。公開した際にはその具体的な設計についてまた書かせていただきます。