MySQLに対するDrizzleの答え #1 スレッド管理編
先日、Drizzleのスレッド管理を担うコアの一部分がモジュール化され、勉強がてらMySQLのスレッド管理の設計を調べてみました。その時のメモ(だから文が少し固いかも)と、Drizzleでの戦略を今回のエントリーで公開します。
最後のDrizzleでは?セクションまではプログラミングの教科書に載っている様な典型的なセオリを述べているだけなので、MySQLのインターナルに詳しい方は最後まで飛ばした方が良いかもしれません。
ちなみにソースはMySQL 5.1とMySQL 6.0のドキュメントです- http://dev.mysql.com/doc/refman/6.0/en/connection-threads.html
- http://dev.mysql.com/doc/refman/5.1/en/connection-threads.html
現在の仕組みと制限
現在のMySQLでは新たなクライエント接続に対して専用スレッドを割り当てるといった古典的なモデルを採用しています。割当を実際に行うのはコネクションマネージャというNetwork Interfaceを監視するスレッドであり、OSによってlistenするインターフェイスが異なります。
マネージャは無駄に新たなスレッドを生む事を避けるために、接続に割り当てるスレッドがキャッシュに存在するかを調べます。役目を終えたスレッドはスレッドキャッシュに空きがあった場合にキャッシュされますが、ない場合は破棄されます。
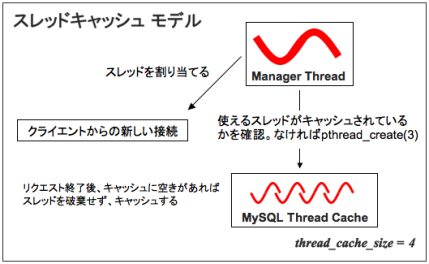
スレッドキャッシング
スレッドキャッシュのサイズはthread_cache_sizeというシステム変数によって定められ、デフォルト値は0です。したがって、デフォルト設定のMySQLは新たな接続に対し新たなスレッドを生成し、接続が完了したらスレッドを破棄するという処理を繰り返します。thread_cache_size変数は起動時と運用中のどちらでも変更する事が可能です。問題点
このモデルの問題点は当然ながら、スレッドの数がクライエント接続数に比例して増えるという事です。連続するスレッド生成と破棄のコストを考慮にいれると、効率のよい仕組みとは呼べません。さらにスレッド数(接続数)の増減に比例して消費するサーバ資源が増えてしまうので、個々のスレッドが持つスタック領域を抑えるという実装になっています。MySQL 6.0.4からの仕組み
従来のモデルで問題視された多くの同時接続を円滑に処理するためにスレッドプーリングが採用されます(実装はされている)。コネクションマネージャは特定の接続にスレッドを割り当てるのではなく、完全にクライエントからのリクエストを受信した後に処理待ちのタスクキューに追加します。サーバはサービススレッドのプールを管理し、処理待ちのリクエストをプール内の使用可能なスレッドに割り当てます。リクエスト処理の終えたスレッドは再び使用可能な状態となり、他リクエストの処理を行います。
ワーカスレッドたちはサーバの起動時に生成され、サーバプロセスが終了するまで生き続け、特定のコネクションに縛られません。また、プールのサイズは固定であるため、消費する資源がコネクション数に比例して増える事がありません。とまあ、典型的なプーリングモデルですね。
スレッドプーリングの弱点
多数のコンプレックス(多めの演算力とI/Oを伴う)クェリーが頻繁に発行される環境では、スレッド数の上限設定が仇になる場合があります。全スレッドが複数のクライエントからのリクエストを処理する場合、当然ながら新たなリクエストに対応する事ができず、サーバが固まってしまいます。この問題はスレッドプールの限界値を上げる事で対処する事が推奨されています。限界値はthread_pool_sizeというシステム変数により定めれており、これを起動時に指定する事で変更が可能です(デフォルト値は20)。運用法や設定
スレッドプーリングはmemcachedで実績があるlibeventを使って実装されており、適用するにはconfigure時に--with-libeventを指定する必要があります。スレッドモデルの選択はサーバの起動時にthread_handlingシステム変数によって判別されます。デフォルトのスレッドマネージメントモデルは接続に対して専属のスレッドが割り当てられる "--thread_handling=one-thread-per-connection"モードです。スレッドプーリングを適用するには、--thread_handling=pool-of-threadsオプションでサーバを起動します。Drizzleでは?
全てのソリューションやアルゴリズムにはユースケースによって必ず何らかの弱点が存在します。Drizzle Projectではサーバの軽量化と同時に、幅広い問題を柔軟に解決するためにMicroKernelアーキテクチャを採用しています。これはスレッドスケジュリングも例外ではなく、MySQLのスレッドマネージメントコードは完全にコアから抜き取られ、分離されています。正確に述べると、MySQL内でいう、one-thread-per-connectionとpool-of-threadsの両モードのコードが完全にモジュール化されています。これは何が嬉しいかといいますと、まずmutexをコアから外部(モジュール)に押し出す事によってlock contentionの対応をサーバから分離できる事です(小人さんがロックレスなモジュールを書いてくれるかも!)。あとは、ソースコードがスマートに整理できるというところでしょうか。例えばスレッドプーリングってどうやって実装されているの?と気になった場合はまずプラグインのインターフェイスを見て、
#ifndef DRIZZLED_PLUGIN_SCHEDULING_H
#define DRIZZLED_PLUGIN_SCHEDULING_H
typedef struct scheduling_st
{
bool is_used;
uint32_t max_threads;
bool (*init_new_connection_thread)(void);
void (*add_connection)(Session *session);
void (*post_kill_notification)(Session *session);
bool (*end_thread)(Session *session, bool cache_thread);
} scheduling_st;
#endif /* DRIZZLED_PLUGIN_SCHEDULING_H */
モジュールの実装(drizzle/pluginディレクトリ以下)を覗くだけで、簡単に読む事ができます。例えばスレッドプーリングの実装だと以下のファイルをお好みのエディタで開くとよいでしょう:
$ vi drizzle/plugin/pool_of_threads/pool_of_threads.cc
とまあ、パッケージ内を比較的簡単に泳ぐ事ができ、システム改善を従来の設計よりも簡単にハックする事が可能です。
まとめ
MySQLのスレッドマネージメントの現在と今後、そして制限や弱点を調査し、メモを公開しました。また、MySQLが抱える、このドメインの問題に体するDrizzleのアプローチも共有し、lock contentionの対応をコアから押し出す利点を紹介しました。今回のエントリーだけだとMicroKernelの詳しい設計やモジュールの事が全然わからん!と突っ込まれそうですが、そこまで書くと膨大なエントリーになりそうなので、また別の機会に紹介します。同時に今後もDrizzle Projectで面白かったり、嬉しいネタが出てきたらちょくちょく共有していきたいと思います。